

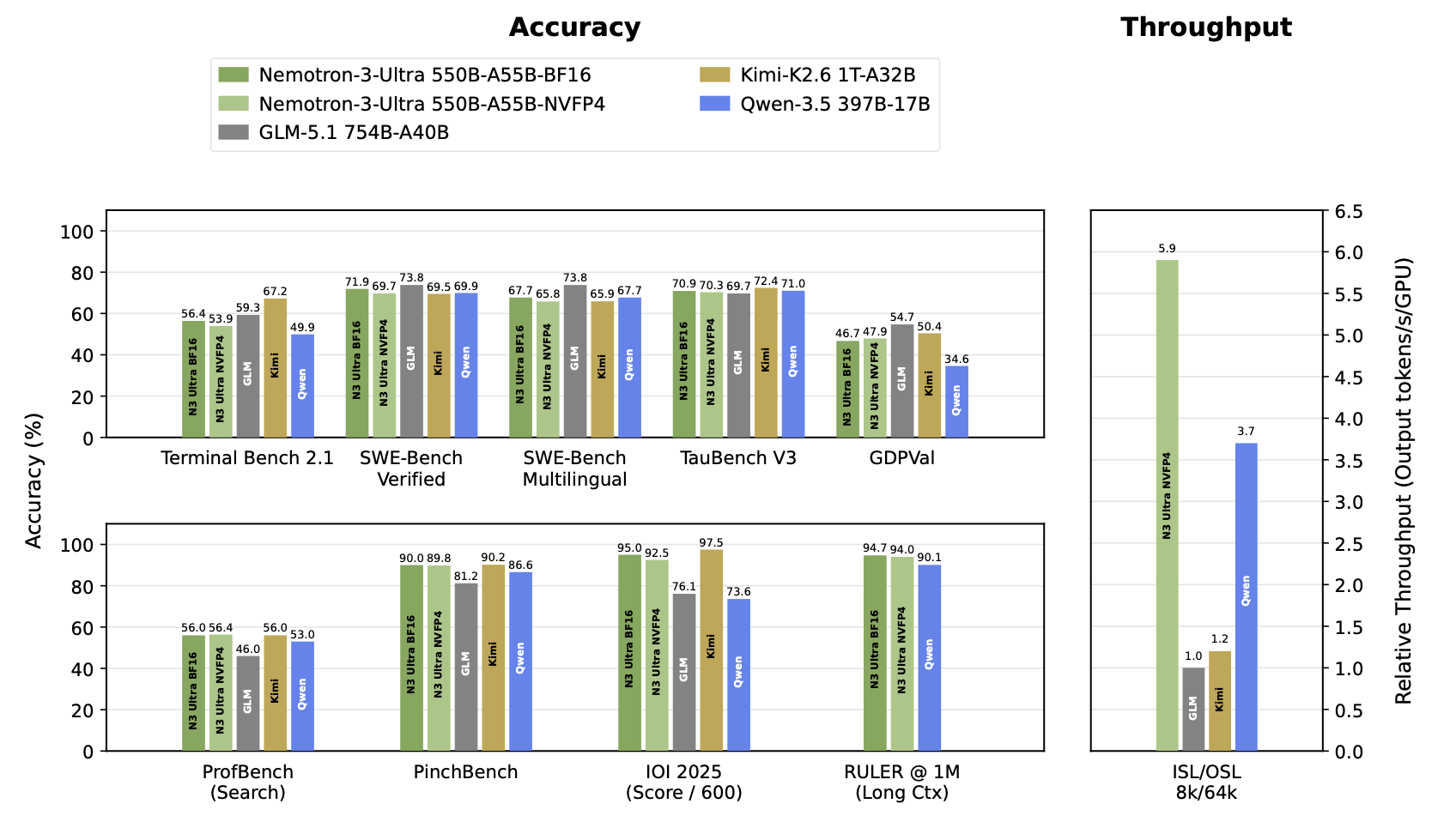
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
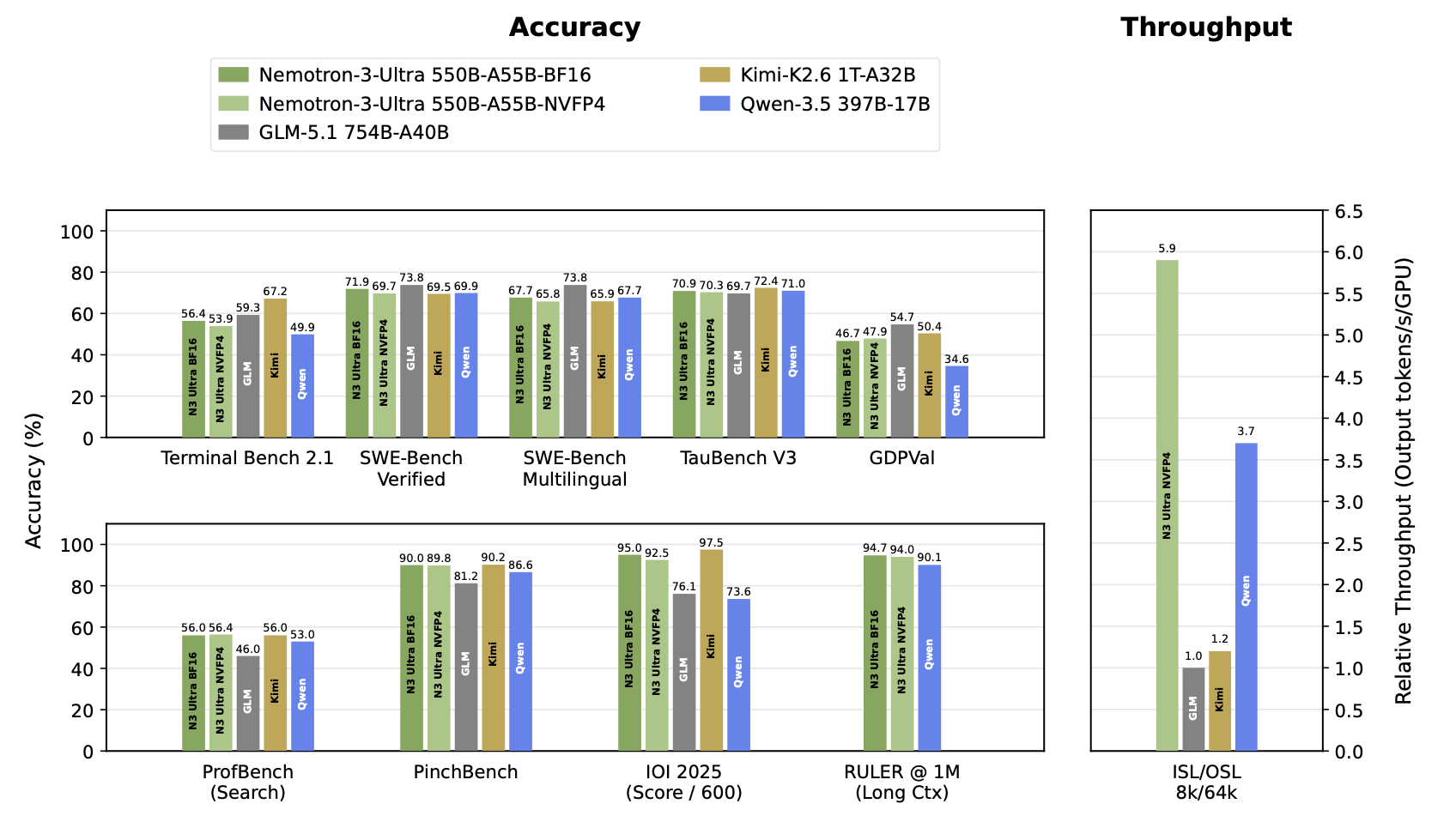
- Xet hash:
- 558c998a5e4b9775aa24ee3d7d8580bbcf2ecbe7fb1d88413fd6e11aa6a41a73
- Size of remote file:
- 249 kB
- SHA256:
- 76451ff3fb7dc9fa1ac796dfb4b713717c357582470e2e6a1817065b4f3770b0
·
Xet efficiently stores Large Files inside Git, intelligently splitting files into unique chunks and accelerating uploads and downloads. More info.