
Gemma-4-E2B Natural Language Autoencoder (Critic), v0.0.1
First open-source NLA released independently of Anthropic's NLA team. Trained end-to-end on a 4 GB consumer GPU. The methodology contribution at small-model scale.
This is the AR (Critic) half of an NLA pair following the methodology of kitft/natural_language_autoencoders (Fraser-Taliente et al., 2026, the official Anthropic reference release). It takes a natural-language explanation and reconstructs the residual-stream activation it was meant to describe — the round-trip test for AV-explanation faithfulness.
For the matched AV (Actor) half, see Solshine/gemma-4-e2b-nla-L23-av-v0_0_1. For the consolidated companion dataset, see Solshine/gemma-4-e2b-deception-behavior-completions.
What's distinctive about this release
- First open-source NLA AR released independently of Anthropic's NLA team. The methodology was Anthropic's (Fraser-Taliente et al. 2026). This is the first community/third-party reproduction.
- First half-precision LoRA AR of the public NLA family. Anthropic's full-finetune AR variants need 14+ GB; this fits on 4 GB.
- AR achieved via LoRA fine-tuning (r=64, alpha=128) on an NF4-quantized truncated Gemma-4-E2B (first 18 of 35 layers + Linear(1536, 1536) projection head). Only ~80 MB trainable LoRA + ~9 MB linear head versus full fine-tuning of billions of params. This is the load-bearing reason the methodology fits on a 4 GB consumer GPU.
- Honest small-model framing. Round-trip cos = 0.438 ± 0.054 on n=42 held-out activations matched-pair with the v0.0.1 AV.
- AR content-blindness disclosure (see below). Cos 0.405 from feeding the AR an empty string vs 0.429 from real explanation — ~95% structural projection, ~5% explanation-dependent at this training scale.
Architecture and training
- Base model.
google/gemma-4-E2Btruncated to the first 18 of 35 text layers + Linear(1536, 1536) head - Layer. L23 (~2/3 through the text-layer stack; reconstruction target layer)
- Quantization. NF4 4-bit base weights plus bf16 LoRA adapters
- LoRA. r=64, alpha=128, regex target restricting to language-model text layers (excludes audio tower):
r"model\.language_model\.layers\.\d+\.(self_attn|mlp)\.(q_proj|k_proj|v_proj|o_proj|gate_proj|up_proj|down_proj)" - AR prompt template.
Summary of the following text: <text>{explanation}</text> <summary> - Suffix-anchored extraction. AR extracts the reconstructed activation from the FINAL token (the trailing space after
<summary>) - MSE objective. L2-normalized prediction vs L2-normalized target, both scaled to
sqrt(d_model) - Optimizer. AdamW 8-bit, lr=1e-4 base then 3e-5 continuation
- Training wall time. ~1.5 GPU-hours
This is the first half-precision LoRA AR of the public NLA family — Anthropic's full-finetune AR variants need 14+ GB; this fits on 4 GB.
How v0.0.1 fits the constraints (the tricks)
Hardware (fit Gemma-4-E2B truncated + AR training on 4 GB VRAM)
- NF4 4-bit base weights. Cuts the ~4 GB bf16 model to ~1 GB.
- AR truncation: first 18 of 35 layers + Linear(1536, 1536) head. Forward pass only through half the model.
- LoRA r=64 on the surviving layers. Only ~80 MB trainable + ~9 MB Linear head.
- bf16 LoRA on top of NF4 base. Mixed precision; gradients fit.
- Gradient checkpointing. Recomputes activations on backward; trades ~30% compute for ~40% VRAM.
- AdamW 8-bit optimizer. Vs 32-bit AdamW, which holds 8 bytes/param of optimizer state and would not fit.
micro_batch=1+grad_accum=16. Effective batch 16 without the VRAM cost of a real batch 16.max_length=512context. Vs 2048+ standard. Cuts activation tensors 4×.- Forward-hook early-exit at layer 18. Skips the second half of the model entirely; saves both compute and VRAM.
- Suffix-anchored activation extraction at tokens[-1]. Single-token output, no scan-for-marker; minimal eval-time memory pressure.
Time (3 weeks of evenings, ~1.5 GPU-hours per full AR run)
- Restart-safe chunked parquet output. Per-batch chunks in a
chunks/subdir; relaunches skip already-done batches. Saved 2+ days when Gemini quota walls hit mid-run. - Watchdog auto-resume across Gemini daily quota cycles. Continues labeling across the 24h reset wall without manual relaunch.
PYTHONUNBUFFERED=1/python -uon every long training run.save_interval=50. First checkpoint lands inside ~2.5 hours of training.- Sidecar
nla_meta.yamlper checkpoint. Eval-provenance lookup in 1 file open.
Budget ($0 cloud, ~$0.50 in API spend total)
- Local 4 GB GPU. Zero cloud compute spend for v0.0.1 training and eval.
- Gemini CLI in YOLO mode under personal Gemini Pro subscription. Free labeling for the v0.1.x diversified corpus.
- Claude Code credits for Claude Haiku labeler. Already paid for; zero marginal cost.
- gpt-4o-mini fallback only when needed. v0.0.1's full original labeling was ~$0.50 total.
- Synthetic personas (Dr Chen + Dr Otsuka) instead of real LLM judges. Two cheap LLM calls per row, no judge-API surcharge.
- HuggingFace free tier for hosting. Model repos + dataset repos at $0/mo.
Methodology (descope stays faithful, not corner-cutting)
- Persona+audit labeling pipeline. Dr Chen labeler then Dr Otsuka auditor.
- Per-row
labeler_modelprovenance column. Future cross-labeler ablations don't need a rerun. - Honest-accuracy training-trend verdict (slope < −0.002/step AND R² ≥ 0.10).
- Data-permanence directive. Commit every parquet to
results/immediately. - Eval-provenance sidecar convention. Commit SHA + parquet SHA-256 + headline cos numbers in YAML.
Software / tooling (Windows-specific gotchas)
shutil.which("gemini")to resolve npm.CMDshims.MSYS_NO_PATHCONV=1 taskkill /F /T /PIDfor stuck Python processes from Git Bash.device_map={"": torch.cuda.current_device()}(integer) not{"": "cuda"}(string).KMP_DUPLICATE_LIB_OK=TRUEprefix on every run.
Total spend for v0.0.1: ~$0.50 in API charges + $0 cloud + electricity for ~6 GPU-hours on a laptop. Time: 3 weeks of evenings.
Honest performance summary

Round-trip cosine similarity distribution on 42 held-out activations. Clean unimodal distribution centered at 0.438 ± 0.054. 100% of evaluated rows clear the 0.30 noise-floor threshold. This is a joint-pair metric (this AR + the matched v0.0.1 AV); see the AV card for the matched view.
| Metric | Value |
|---|---|
| Round-trip cosine similarity (mean) | 0.438 ± 0.054 |
| Round-trip cosine similarity (median) | 0.434 |
| Round-trip MSE (mean) | 1.124 (vs random baseline 2.0) |
| Rows above 0.30 noise-floor | 42 / 42 (100%) |
| n_evaluated | 42 of 50 attempted. 8 produced empty AV outputs and were excluded |
| Min row cos | 0.313 |
| Max row cos | 0.558 |
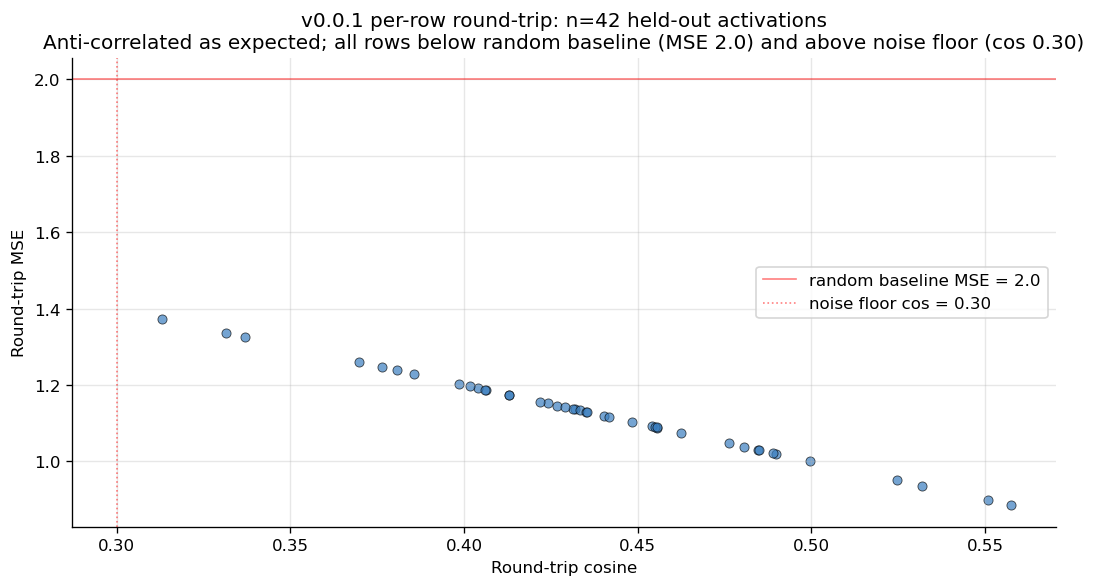
Per-row round-trip cos for the 42 evaluated rows. Horizontal line at 0.30 is the noise floor. No degenerate rows. Useful for visualizing the spread that the 0.438 ± 0.054 summary collapses.
Round-trip cos is the matched AV+AR pair on held-out OpenWebText activations. The eval is symmetric: round-trip cos quality is co-determined by both halves of the pair, so this number is the AR's quality marker as much as the AV's.
Honest failure-rate disclosure. 16% of attempted eval rows (8 of 50) produced empty AV outputs and were excluded from the cos calculation. The empty-output mode is on the AV side, not this AR, but it is the joint pair's failure rate at eval time. That is a real failure mode of the small-model variant, not a quirk of the eval set. The v0.1.x release with the diversified 9-source-family corpus and a longer SFT step budget is the test of whether scale fixes it.
⚠ Read this before using v0.0.1 for interpretability work
This AR is content-blind under v0.0.1 training. A targeted ablation (documented in full in ACCURACY_COLLAPSE_LIMITATIONS_ROOT_CAUSES_HYPOTHESIS.md) showed:
| AR input on the same target activations | Mean cos | Above 0.30 floor |
|---|---|---|
| Real AV-generated explanation | 0.4292 | 10/10 |
| Random unrelated Wikipedia sentences | 0.4045 | 10/10 |
Random nonsense tokens ("qwop fnar blarp...") |
0.4135 | 10/10 |
| Empty string | 0.4051 | 10/10 |
The AR produces nearly the same cos regardless of what text you feed it. The explanation contributes a mean +0.024 cos delta over empty-string input. About 95% of the published joint-pair cos number comes from this AR's content-independent projection toward OpenWebText activation space.
This means: the round-trip cos 0.438 reported on the matched v0.0.1 pair is principally measuring the AR's structural projection, not explanation faithfulness. It is not a defect in this AR specifically — both halves of the pair were under-trained (the AR saw roughly the same fraction of its training data as the AV did under SFT). It is a fact about what the joint-pair metric measures at v0.0.1 scale.
Practical implication: do not pair this AR with a different-source AV expecting cos to reflect explanation quality; cos will be near 0.40 regardless of what the AV produces. The AR is provided for matched-pair reproduction of the published v0.0.1 numbers and as a baseline for future AR retraining experiments.
What this artifact is and is not
The v0.0.1 AR is most useful for:
- ✅ Pairing with the matched v0.0.1 AV for round-trip eval and replication of the methodology pipeline
- ✅ Activation reconstruction from text at the noise-floor-clearing cos level
- ✅ Baseline for v0.1.0 AR scaling experiments when the matched diversified v0.1.x AV lands
- ✅ Stage-0 input to cross-AR ablation studies in the consumer-GPU regime
The v0.0.1 AR is NOT yet useful for:
- ❌ Pairing with arbitrary third-party AV checkpoints — has not been validated outside the matched v0.0.1 pair
- ❌ Certifying per-row faithfulness — round-trip cos is a joint-pair metric and does not on its own adjudicate per-row AV explanation quality (per the template-collapse finding above)
- ❌ Reconstructing activations from explanations that are wildly different from the 4 training-time stems — performance on out-of-distribution AV outputs is unknown
Available HF datasets
Solshine/gemma-4-e2b-nla-ar_sft-v0_0_x-haiku-persona-audit— 696-row AR-SFT training corpus, Claude Haiku persona+audit. The exact training dataset this AR was fine-tuned on for the matched v0.0.x persona+audit variant.Solshine/gemma-4-e2b-nla-av_sft-v0_1_x-gemini-persona-audit— 4,734-row AV-SFT diversified training corpus (companion side, for v0.1.x).Solshine/gemma-4-e2b-deception-behavior-completions— 910-row companion deception/behavior corpus.
Intended use
- Round-trip eval of any candidate AV checkpoint targeting Gemma-4-E2B L23
- Stage-0 input for cross-AR ablation studies in the consumer-GPU regime
- Baseline AR for future small-model NLA work targeting Gemma-4-E2B
- Activation-reconstruction component in deception-research or safety-monitoring pipelines
Limitations
- Pair with the matched v0.0.1 AV. Mixing this AR with a third-party AV has not been validated.
- Round-trip cos at the joint pair's level is symmetric: a comparable cos can be obtained from AV templates of varying per-row diversity, so cos alone does not adjudicate AV explanation faithfulness. The matched v0.0.1 AV shows 20 unique full-explanation strings across 42 rows (52% exact-duplicate rate) and 4 opening template stems; full root-cause analysis in
ACCURACY_COLLAPSE_LIMITATIONS_ROOT_CAUSES_HYPOTHESIS.md. Future releases will report per-row template diversity alongside cos. - Training corpus is OpenWebText-only. v0.1.0 with diversified labels across 10 source families is in progress.
- Round-trip cos = 0.438 is below Anthropic's published 7B numbers (~0.7+). Use for methodology replication, not absolute performance matching.
- Linear(1536, 1536) head is loaded separately from the LoRA adapter (
linear_head.pt).
How to use
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
bnb = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4", bnb_4bit_use_double_quant=True)
base = AutoModelForCausalLM.from_pretrained("google/gemma-4-E2B", quantization_config=bnb,
device_map={"": torch.cuda.current_device()})
ar = PeftModel.from_pretrained(base, "Solshine/gemma-4-e2b-nla-L23-ar-v0_0_1")
tok = AutoTokenizer.from_pretrained("google/gemma-4-E2B")
linear_head_state = torch.load("linear_head.pt") # download separately from this repo
# For a complete, self-contained round-trip inference example,
# see `examples/round_trip_example.py` in the public bundled release:
# https://github.com/SolshineCode/nla-gemma-4-e2b
Citation
@misc{gemma4_e2b_nla_v0_0_1_ar,
title = {Gemma-4-E2B Natural Language Autoencoder (Critic) v0.0.1: the first consumer-GPU-trainable open NLA},
author = {SolshineCode},
year = {2026},
month = {may},
url = {https://huggingface.co/Solshine/gemma-4-e2b-nla-L23-ar-v0_0_1}
}
Please also cite the upstream NLA methodology:
- Fraser-Taliente, K., et al. (2026). Natural Language Autoencoders. https://transformer-circuits.pub/2026/nla/
kitft/natural_language_autoencoders. Anthropic's official reference NLA training pipeline.
See also
- Source research repo.
SolshineCode/deception-nanochat-sae-research— currently private, available upon request — DM me. - Matched AV.
Solshine/gemma-4-e2b-nla-L23-av-v0_0_1 - Companion dataset.
Solshine/gemma-4-e2b-deception-behavior-completions
- Downloads last month
- 100
Model tree for Solshine/gemma-4-e2b-nla-L23-ar-v0_0_1
Base model
google/gemma-4-E2B