
SynFlow: Scaling Up LiDAR Scene Flow Estimation with Synthetic Data
Paper • 2604.09411 • Published
Error code: StreamingRowsError
Exception: ArrowInvalid
Message: Mismatching child array lengths
Traceback: Traceback (most recent call last):
File "/src/services/worker/src/worker/utils.py", line 147, in get_rows_or_raise
return get_rows(
dataset=dataset,
...<4 lines>...
column_names=column_names,
)
File "/src/libs/libcommon/src/libcommon/utils.py", line 272, in decorator
return func(*args, **kwargs)
File "/src/services/worker/src/worker/utils.py", line 127, in get_rows
rows_plus_one = list(itertools.islice(safe_iter(ds, dataset=dataset), rows_max_number + 1))
File "/src/services/worker/src/worker/utils.py", line 478, in safe_iter
yield from ds.decode(False) if ds.features else ds
File "/usr/local/lib/python3.14/site-packages/datasets/iterable_dataset.py", line 2818, in __iter__
for key, example in ex_iterable:
^^^^^^^^^^^
File "/usr/local/lib/python3.14/site-packages/datasets/iterable_dataset.py", line 2355, in __iter__
for key, pa_table in self._iter_arrow():
~~~~~~~~~~~~~~~~^^
File "/usr/local/lib/python3.14/site-packages/datasets/iterable_dataset.py", line 2380, in _iter_arrow
for key, pa_table in self.ex_iterable._iter_arrow():
~~~~~~~~~~~~~~~~~~~~~~~~~~~~^^
File "/usr/local/lib/python3.14/site-packages/datasets/iterable_dataset.py", line 536, in _iter_arrow
for key, pa_table in iterator:
^^^^^^^^
File "/usr/local/lib/python3.14/site-packages/datasets/iterable_dataset.py", line 419, in _iter_arrow
for key, pa_table in self.generate_tables_fn(**gen_kwags):
~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^
File "/usr/local/lib/python3.14/site-packages/datasets/packaged_modules/hdf5/hdf5.py", line 87, in _generate_tables
pa_table = _recursive_load_arrays(h5, self.info.features, start, end)
File "/usr/local/lib/python3.14/site-packages/datasets/packaged_modules/hdf5/hdf5.py", line 273, in _recursive_load_arrays
arr = _recursive_load_arrays(dset, features[path], start, end)
File "/usr/local/lib/python3.14/site-packages/datasets/packaged_modules/hdf5/hdf5.py", line 294, in _recursive_load_arrays
sarr = pa.StructArray.from_arrays(values, names=keys)
File "pyarrow/array.pxi", line 4306, in pyarrow.lib.StructArray.from_arrays
File "pyarrow/error.pxi", line 155, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 92, in pyarrow.lib.check_status
raise convert_status(status)
pyarrow.lib.ArrowInvalid: Mismatching child array lengthsNeed help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
The SynFlow dataset is a synthetic LiDAR scene flow benchmark collected using the CARLA simulator, and is formatted for seamless compatibility with OpenSceneFlow. We provide both the full dataset and two pretrained model checkpoints (one trained on the SynFlow-4k dataset, and another on SynFlow-4k augmented with real-world data; both are trained with DeltaFlow backbone) to support further research and development by the community. Check licenses for more detail usage.
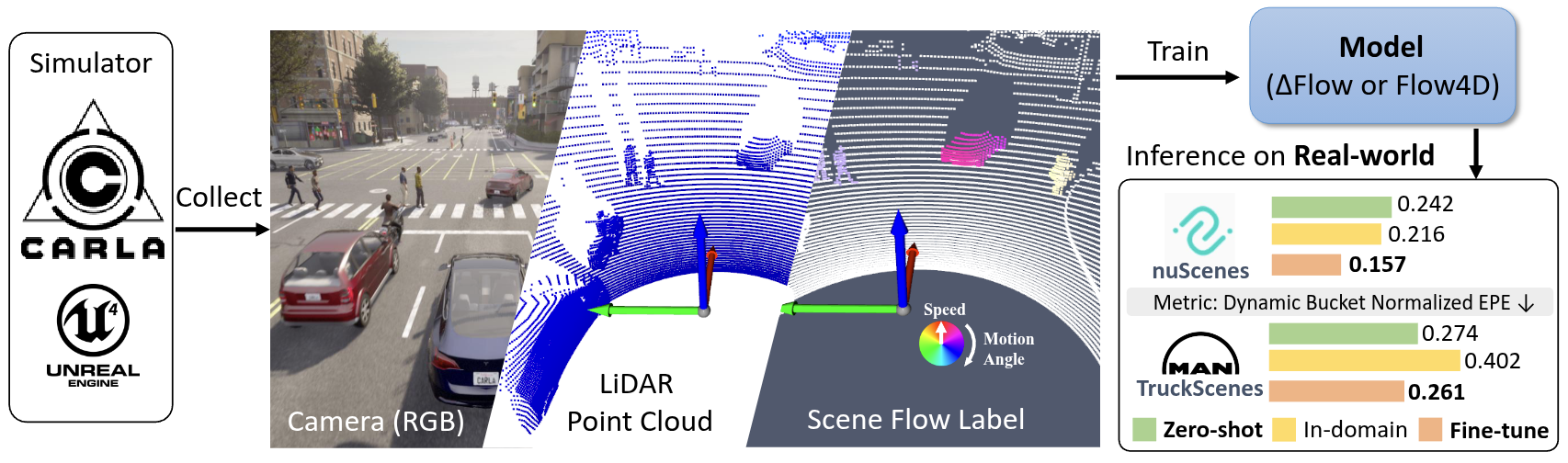
SynFlow dataset provides dense 3D scene-flow ground truth for autonomous-driving research. An ego vehicle drives along pre-defined routes in multiple CARLA towns while a LiDAR captures point clouds at 10 Hz. Each scene is stored as a separate HDF5 file and spans roughly 20 seconds (~200 frames for 64-beam LiDAR, ~30 s / 302 frames for 32-beam LiDAR). Dynamic objects (vehicles, pedestrians, cyclists, etc.) receive instance-level rigid-body flow labels; static background points receive ego-motion-compensated flow.
Folder Structure
town-data-folder/
├── scene-{town}{channels}{route_id:04d}{split:02d}.h5 # one file per scene
├── ...
├── index_total.pkl # frame index for training / visualization
...
# The backbone here is *DeltaFlow*
model-ckpt/
├── synflow-4k-longadp.ckpt # the ckpt trained only on our SynFlow-4k dataset
├── synflow-real-longadp.ckpt # the ckpt trained on our SynFlow-4k dataset and real-world dataset (Av2, Waymo, nuscene)
routes-xml/ # generate from our code, check: https://github.com/Kin-Zhang/SynFlow
├── town01.xml
├── ...
└── town12.xml
Data Split
Here is the data split presented in our SynFlow paper Tab. 1, with the folder name and composition.
| Split | # Annotated Frames | Folder Name | Composition | Storage Size (GB) |
|---|---|---|---|---|
| 1k | 271, 148 | town-06-07-10 |
Town06, 07, 10 arterials, complex junctions, rural roads | 214G |
| 2k | 449,407 | town-01-05 |
Town01–05 roundabouts, multi-lane intersections | 419G |
| 3k | 720,555 | town-06-07-10 + town-01-05 |
Town06-07-10, Town01-05 | 633G |
| 4k | 939,083 | town-01-05 + town-12 |
Town01-05, Town12 | 986G |
Command for Download
# full
hf download KTH/SynFlow --repo-type dataset --local-dir ./SynFlow-data
# 1k split (for a quick training test) around 214G
hf download KTH/SynFlow --repo-type dataset --include "town-06-07-10/*" --local-dir ./SynFlow-data/town-06-07-10
File Naming Convention: scene-{town_id}{channels}{route_id:04d}{scene_split:02d}.h5,
where town_id is the CARLA town number (e.g. 01, 12),channels is LiDAR beam count (32, 64),route_id is a 4-digit route index (e.g. 0042),
and scene_split is a 2-digit split for long routes (00, 01, etc).
Example: scene-0164004200.h5 → Town01, 64-beam LiDAR, route 42, split 0. Scenes with fewer than 120 valid frames are discarded during collection.
This dataset is generated by SynFlow-Github. See the repository for route generation, multi-instance collection, and configuration details.
| Property | Value |
|---|---|
| Simulator | CARLA 0.9.16 |
| Sensor | sensor.lidar.ray_cast_semantic |
| Frame rate | 10 Hz (fixed_delta_seconds = 0.1) |
| Coordinate system | Right-handed (RHS); Y-axis flipped from CARLA's native left-handed system |
| Ego vehicle | Tesla Model 3 with BehaviorAgent route following |
| NPCs | ~70 vehicles + ~80 pedestrians per scene (town-dependent) |
| Towns | Town01–Town10, Town12 (diverse urban, highway, rural, and large-map environments) |
LiDAR Configurations
| Channels | Range | FOV (upper / lower) | Points/sec | Frames / scene | Duration |
|---|---|---|---|---|---|
| 64 | 85 m | +10° / −30° | 460,000 | 201 | ~20 s |
| 32 | 75 m | +10° / −30° | 160,000 (typical) | 302 | ~30 s |
Default: LiDAR is mounted at z = 2.1 m above the ego vehicle origin.
Each HDF5 file contains one scene. Every frame is stored as an HDF5 group keyed by its simulation timestamp in microseconds (e.g. "1577836800000000"). There is no separate timestamps dataset—the group key is the timestamp.
| Key | Shape | Dtype | Description |
|---|---|---|---|
lidar |
(N, 3) |
float32 |
Point cloud in sensor frame (X, Y, Z), RHS |
pose |
(4, 4) |
float64 |
Ego vehicle 4×4 transformation matrix (world ← ego), RHS |
flow |
(N, 3) |
float32 |
Scene-flow vector from frame t to t+1 in sensor frame, RHS |
flow_is_valid |
(N,) |
bool |
Per-point flow validity mask (currently all True) |
flow_category_indices |
(N,) |
uint8 |
Semantic category index; 0 = background/static |
flow_instance_id |
(N,) |
int16 |
Instance ID; -1 = background, positive = dynamic object |
ground_mask |
(N,) |
bool |
True for ground points (road, sidewalk, terrain, road line, ground) |
N varies per frame depending on LiDAR density and scene complexity.
flow_instance_id: dynamic objects are labeled with npc.id % 32000 + 1; background is -1 (training code uses 0-indexed instances, so background must not be 0).flow_category_indices: maps to the AnnotationCategories enum used in OpenSceneFlow (e.g. REGULAR_VEHICLE, PEDESTRIAN, TRUCK, BICYCLE, MOTORCYCLE, BUS, …). Index 0 denotes background / static.ground_mask is True for points whose CARLA semantic tag is one of {Road, SideWalk, Terrain, RoadLine, Ground} (tags 1, 2, 10, 24, 25).
Index Files
index_total.pkl is a pickled list of [scene_id, timestamp] pairs covering all frames, required for OpenSceneFlow training and visualization:
import pickle
with open("index_total.pkl", "rb") as f:
index = pickle.load(f) # e.g. [["scene-0164004200", "1577836800000000"], ...]
index_eval.pkl (optional) subsamples every 5 frames with a minimum non-ground point count, for standardized evaluation.
HDF5 File Example
import h5py
import numpy as np
scene_id = "scene-0164004200"
timestamp = "1577836800000000"
with h5py.File(f"{scene_id}.h5", "r") as f:
frame = f[timestamp]
points = frame["lidar"][:] # (N, 3) float32
pose = frame["pose"][:] # (4, 4) float64
flow = frame["flow"][:] # (N, 3) float32
valid = frame["flow_is_valid"][:] # (N,) bool
cats = frame["flow_category_indices"][:] # (N,) uint8
inst = frame["flow_instance_id"][:] # (N,) int16
ground = frame["ground_mask"][:] # (N,) bool
# Dynamic (non-background) points
dynamic_mask = inst != -1
For visualization and training, use the OpenSceneFlow toolchain:
python tools/visualization.py --res_name flow --data_dir /path/to/data
For training, please follow the OpenSceneFlow to setup environment and change the data path to this dataset, example command:
python train.py slurm_id=$SLURM_JOB_ID wandb_mode=online wandb_project_name=synflow \
train_data="['data/town-06-07-10', 'SynFlow/data/town-01-05', 'SynFlow/data/town-12']" \
val_data='$DATA_DIR/val' model=deltaflow loss_fn=deltaflowLoss model.target.decoder_option=default \
num_workers=16 num_frames=5 model.target.decay_factor=0.4 epochs=21 batch_size=2 \
save_top_model=3 val_every=3 train_aug=True "voxel_size=[0.15, 0.15, 0.15]" "point_cloud_range=[-38.4, -38.4, -3, 38.4, 38.4, 3]" \
optimizer.lr=2e-4 +optimizer.scheduler.name=StepLR +optimizer.scheduler.step_size=3 +optimizer.scheduler.gamma=0.9
If you use this dataset, please cite our papers (datasets and models), more works on OpenSceneFlow.
@article{zhang2026synflow,
author = {Zhang, Qingwen and Zhu, Xiaomeng and Jiang, Chenhan and Jensfelt, Patric},
title = {{SynFlow}: Scaling Up LiDAR Scene Flow Estimation with Synthetic Data},
journal = {arXiv preprint arXiv:2604.09411},
year = {2026},
}
@inproceedings{zhang2025deltaflow,
title={{DeltaFlow}: An Efficient Multi-frame Scene Flow Estimation Method},
author={Zhang, Qingwen and Zhu, Xiaomeng and Zhang, Yushan and Cai, Yixi and Andersson, Olov and Jensfelt, Patric},
booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems},
year={2025},
url={https://openreview.net/forum?id=T9qNDtvAJX}
}
synflow-4k-longadp.ckpt) are released under CC BY 4.0. You are free to share, adapt, and use them for any purpose, including commercial use, as long as you provide appropriate credit (see Citation).synflow-real-longadp.ckpt) remain subject to Argoverse 2, Waymo Open Dataset, and nuScenes licenses. Note that checkpoints trained on real-world datasets are not available for commercial use because of the restrictions of the real-world datasets. Please refer to the respective licenses for more details.